- 서버전문업체 아이티마야
- HPC서버
-
GPU서버
-
4GPU Server
-
8GPU Server
-
HGX Server
-
2GPU Workstation
-
4GPU Workstation
-
Compact AI
-
10GPU Server
-
- BigData서버
- 가상화/HCI
- 스토리지/파일서버
- WEB/WAS/DB
- 워크스테이션
-
MLOps/SW지원/유지보수
-
Cloud
-
Open Source
-
NVIDIA
-
HCI
-
Backup
-
MLOps
-
HW/SW 유지보수
-
AS
-
테크니컬 스토리
아이티마야의 새로운 기술 뉴스를 만나보세요.Pytorch DDP
등록일
2026.05.20
첨부파일
대규모 분산 학습을 위한 DDP 아키텍처 이해
Pytorch DDP

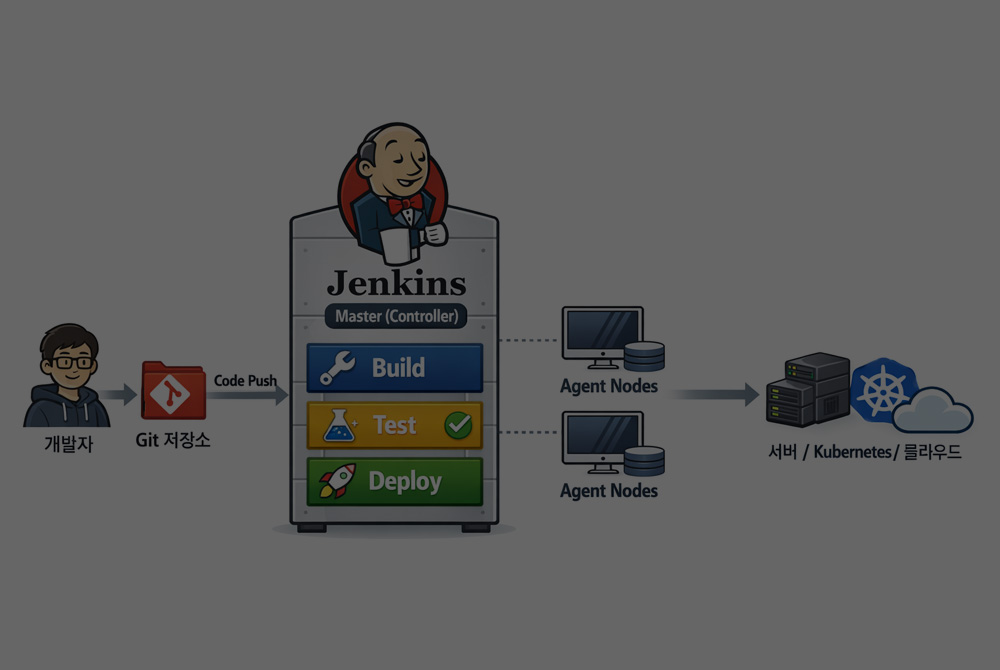
DDP를 사용하는 이유
PyTorch Distributed Data Parallel(DDP)은
대규모 딥러닝 학습에서 다음과 같은 문제를 해결하기 위해 사용됩니다.
- •단일 GPU 환경에서의 학습 시간 증가 문제
- •대용량 데이터 처리 시 병목 발생
- •GPU 자원 활용 비효율
DDP는 데이터를 여러 프로세스로 분산하여 병렬 처리하고,
각 프로세스 간 Gradient를 동기화함으로써 학습 속도를 향상시킵니다.
또한 CPU와 GPU 환경에서 동일한 구조로 동작하기 때문에,
초기 개발 및 검증 이후 별도의 구조 변경 없이 확장이 가능합니다.
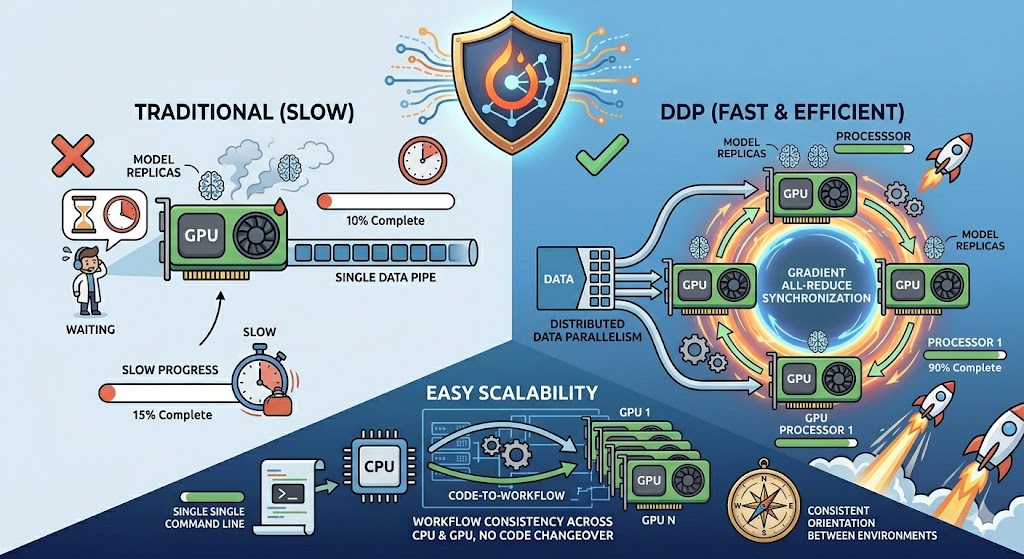
DDP의 장점
1.높은 성능 및 확장성
•멀티 GPU 환경에서 학습 속도 향상
•GPU 수 증가에 따른 수평 확장 가능
2.안정적인 분산 구조
•Multi-process 기반으로 병목 최소화
•기존 DataParallel 대비 효율적
3.하드웨어 독립성
•CPU / GPU 동일 구조 사용
•테스트 → 운영 환경 전환 용이
4.표준 기술
•PyTorch 공식 권장 방식
•다양한 인프라(Slurm, Docker)와 호환
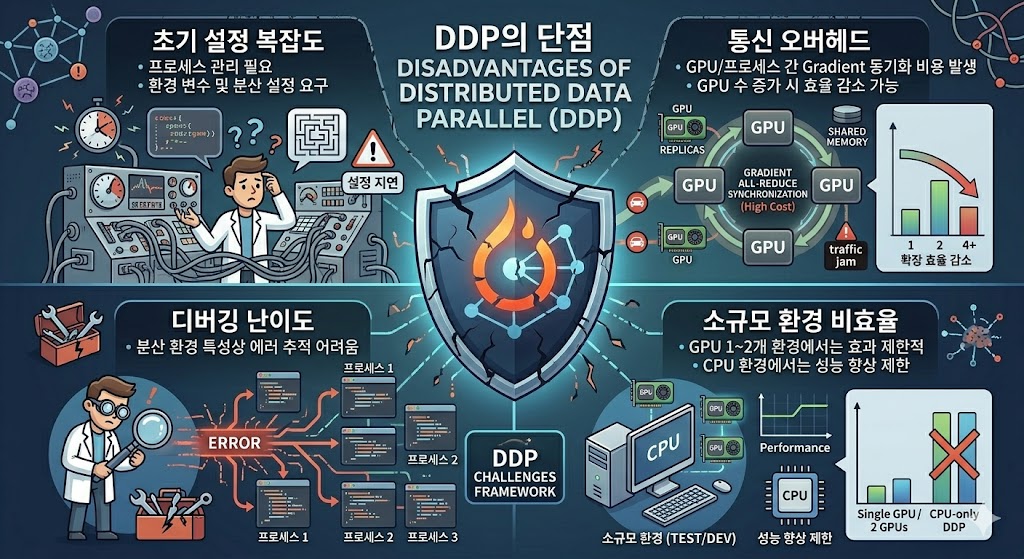
DDP의 단점
1.초기 설정 복잡도
•프로세스 관리 필요
•환경 변수 및 분산 설정 요구
2.통신 오버헤드
•GPU/프로세스 간 Gradient 동기화 비용 발생
•GPU 수 증가 시 효율 감소 가능
3.디버깅 난이도
•분산 환경 특성상 에러 추적 어려움
4.소규모 환경 비효율
•GPU 1~2개 환경에서는 효과 제한적
•CPU 환경에서는 성능 향상 제한
2. 테스트 목적
- •DDP 분산 학습 구조 검증
- •프로세스 간 통신 정상 동작 확인
- •멀티 GPU 확장을 위한 사전 검증
3. 테스트 환경
| 항목 | 내용 |
|---|---|
| OS | Ubuntu 22.04 |
| CPU | Multi-core (4core 이상 권장) |
| Framework | PyTorch 2.x |
| Backend | gloo |
4. DDP 구조 (CPU 기준)
- •프로세스 단위 분산 처리
- •데이터 병렬 처리 (DistributedSampler)
- •Gradient 동기화 (All-Reduce)
👉 GPU 환경과 동일 구조
(통신 backend만 gloo → NCCL 변경)
5. 테스트 시나리오
| 프로세스 수 | 설명 |
|---|---|
| 1 | 단일 프로세스 |
| 2 | DDP 적용 |
| 4 | 확장성 테스트 |
6. 테스트 결과 (예시)
| 프로세스 수 | 수행 시간 | 비고 |
|---|---|---|
| 1 | 100초 | 기준 |
| 2 | 110초 | 통신 오버헤드 발생 |
| 4 | 130초 | 확장성 검증 목적 |
7. 결과 분석
- •CPU 환경에서는 성능 향상이 제한적
- •프로세스 간 통신 비용으로 인해 오히려 지연 발생
👉 그러나
- •분산 처리 구조 정상 동작 확인
- •데이터 분산 및 Gradient 동기화 검증 완료
8. GPU 환경 확장성
DDP는 CPU와 GPU에서 동일한 구조로 동작하며, 아래와 같은 변경만으로 GPU 환경 적용이 가능합니다.
- •backend: gloo → NCCL
- •모델 및 데이터 CUDA 적용
- •GPU ID 매핑
👉 즉,
추가적인 아키텍처 변경 없이 GPU 확장 가능
9. 결론
본 테스트를 통해 CPU 환경에서도 DDP 기반 분산 학습 구조가 정상적으로 동작함을 확인하였으며,
동일한 구조를 기반으로 GPU 환경에 적용 시 성능 향상을 기대할 수 있습니다.
이는 향후 GPU 클러스터 및 대규모 AI 학습 인프라 구축 시 안정적인 확장 기반으로 활용될 수 있습니다.