- 서버전문업체 아이티마야
- HPC서버
-
GPU서버
-
4GPU Server
-
8GPU Server
-
HGX Server
-
2GPU Workstation
-
4GPU Workstation
-
나라장터 등록제품
-
Compact AI
-
10GPU Server
-
- BigData서버
- 가상화/HCI
- 스토리지/파일서버
-
WEB/WAS/DB
-
WEB Server
-
WAS Server
-
고성능 DB
-
타워형서버
-
나라장터 등록제품
-
-
워크스테이션
-
1CPU Workstation
-
2CPU Workstation
-
나라장터 등록제품
-
-
MLOps/SW지원/유지보수
-
Cloud
-
Open Source
-
NVIDIA
-
HCI
-
Backup
-
MLOps
-
HW/SW 유지보수
-
테크니컬 스토리
아이티마야의 새로운 기술 뉴스를 만나보세요.아파치 카프카 (Apache Kafka)
등록일
2023.02.13
첨부파일
오픈소스 분산형 스트리밍 플랫폼 - Apache Kafka
아파치 카프카 (Apache Kafka)
- Apache Kafka 란?
Apache Kafka는 오픈소스 분산 스트리밍 플랫폼이며 주로 데이터 파이프 라인을 만들 때 사용되는 솔루션입니다.
Apache Kafka 용어 설명
1. 브로커 (Broker) : 카프카가 설치되어 있는 서버 혹은 노드 등을 브로커라고 합니다. 브로커는 프로듀서에게서 전달받은 메시지를 수집, 전달 역할을 합니다.
2. 프로듀서 (producer) : 프로듀서 API를 통해 메시지를 브로커에게 보내는역할을 합니다.
3. 컨슈머 (consumer) : 컨슈머 API를 통해 브로커에서 메시지를 받는 역할을 합니다.
4. 주키퍼 (Zookeeper) : 다수의 카프카 클러스터를 관리하기 위한 관리도구입니다.
5. 토픽 (topic) : 카프카는 메시지를 토픽에 따라 분리할 수 있고 프로듀서와 컨슈머는 특정 토픽의 메시지를 송수신할 수 있습니다.
1. 브로커 (Broker) : 카프카가 설치되어 있는 서버 혹은 노드 등을 브로커라고 합니다. 브로커는 프로듀서에게서 전달받은 메시지를 수집, 전달 역할을 합니다.
2. 프로듀서 (producer) : 프로듀서 API를 통해 메시지를 브로커에게 보내는역할을 합니다.
3. 컨슈머 (consumer) : 컨슈머 API를 통해 브로커에서 메시지를 받는 역할을 합니다.
4. 주키퍼 (Zookeeper) : 다수의 카프카 클러스터를 관리하기 위한 관리도구입니다.
5. 토픽 (topic) : 카프카는 메시지를 토픽에 따라 분리할 수 있고 프로듀서와 컨슈머는 특정 토픽의 메시지를 송수신할 수 있습니다.
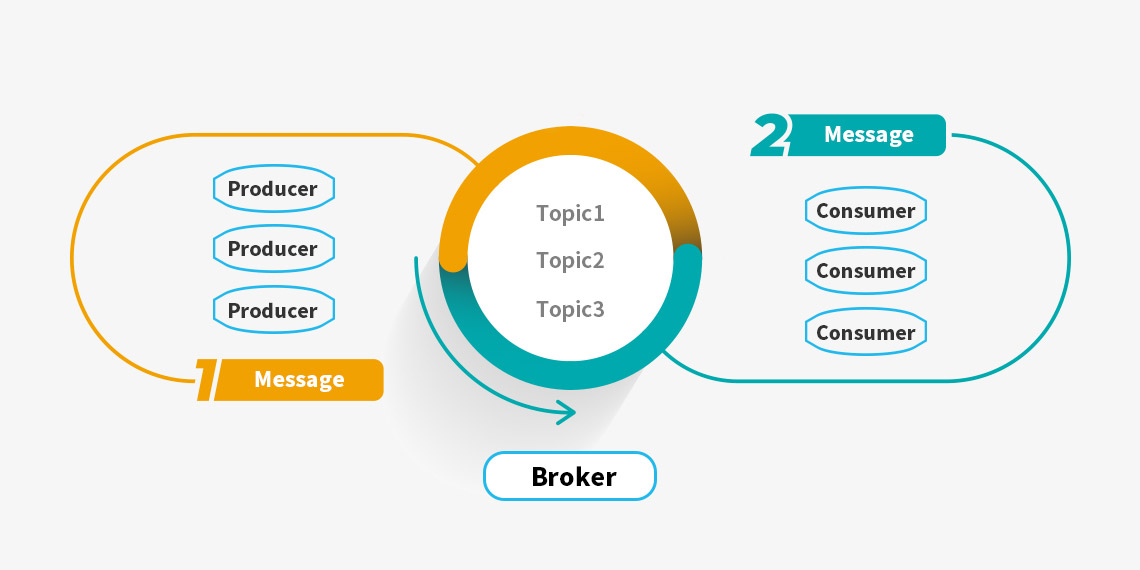
- 카프카의 특징 :
● 카프카는 Producer와 Consumer를 분리하며, 단일 Producer, Consumer 가 아닌 멀티 Producer와 멀티 Consumer로 구성이 가능합니다.
● 카프카 클러스터는 주키퍼와 연동하여 사용합니다, 주키퍼에는 리더, 팔로워라는 개념이 있고 주키퍼 서버에서 브로커 파티션의 리더를 정해주고 리더 파티션의 장애가 발생했을 시 주키퍼에서 다른 브로커의 파티션을 리더를 위임해 정상적으로 운영될 수 있게끔 합니다.
● 주키퍼는 홀수의 서버로 동작합니다. 카프카 클러스로 운영시 최소 3대 이상의 주키퍼 서버로 구성하길 권장합니다. 그 이유는 분산 코디네이션 환경에서 예상치 못한 장애가 발생하더라도 분산 시스템의 일관성을 유지시키기 위해서 사용합니다.
[ Apache Kafka에서 Kafka 4.0 이후부터 주키퍼를 제거할 계획이라고 합니다 ]
● 카프카 클러스터는 주키퍼와 연동하여 사용합니다, 주키퍼에는 리더, 팔로워라는 개념이 있고 주키퍼 서버에서 브로커 파티션의 리더를 정해주고 리더 파티션의 장애가 발생했을 시 주키퍼에서 다른 브로커의 파티션을 리더를 위임해 정상적으로 운영될 수 있게끔 합니다.
● 주키퍼는 홀수의 서버로 동작합니다. 카프카 클러스로 운영시 최소 3대 이상의 주키퍼 서버로 구성하길 권장합니다. 그 이유는 분산 코디네이션 환경에서 예상치 못한 장애가 발생하더라도 분산 시스템의 일관성을 유지시키기 위해서 사용합니다.
[ Apache Kafka에서 Kafka 4.0 이후부터 주키퍼를 제거할 계획이라고 합니다 ]
- 안정성 :
● 다른 메시지 시스템과는 다르게 카프카는 메시지를 디스크에 순차적으로 저장합니다. 이로 인해 서버에 장애가 발생해도 디스크에 메시지를 저장하기 때문에 유실될 걱정이 없습니다.
● 카프카에서 replication 동작으로 브로커 하나가 종료되더라도 운영에 차질이 없습니다.
● 카프카에서 replication 동작으로 브로커 하나가 종료되더라도 운영에 차질이 없습니다.
- 카프카를 사용하는 이유 :
● 카프카는 클러스터로도 운영되기 때문에 확장이 편리하고 장애에 대한 대처가 쉽습니다.
● 메시지를 디스크에 저장하기 때문에 유실될 걱정이 없는 안정성이 있습니다.
● 카프카는 메시지를 병렬로 처리하기 때문에 데이터를 더 효과적으로 저장할 수 있습니다.
● 메시지를 디스크에 저장하기 때문에 유실될 걱정이 없는 안정성이 있습니다.
● 카프카는 메시지를 병렬로 처리하기 때문에 데이터를 더 효과적으로 저장할 수 있습니다.
- 설치 서버 스펙
- 환경 : VM
- CPU : 8 Core
- Memory : 8GB
- OS : ubuntu 22.04
- CPU : 8 Core
- Memory : 8GB
- OS : ubuntu 22.04
- 싱글노드 설치 예제
사전 설치
- kafka 구성 전 java를 설치해 줍니다.
- $ apt install
default -jre - $ java --version 명령어를 통해 java 버전을 확인
- $ apt install
default -jdk - $ javac -version 명령어를 통해 javac 버전 확인
kafka용 유저 생성
- sudo 권한을 가진 kafka용 유저를 생성해 줍니다
- $ sudo adduser kafka
- $ sudo adduser kafka sudo
kafka 바이너리 다운로드 및 추출
- $ sudo mkdir ~/Downloads
- $ sudo curl "https://downloads.apache.org/kafka/3.3.2/kafka_2.13-3.3.2.tgz" -o ~/Downloads/kafka.tgz
- $ mkdir ~/kafka && cd ~/kafka
- $ tar -xvzf ~/Downloads/kafka.tgz --strip 1
- - 압축풀때 현재 kafka디렉토리에 위치하고 있는지 확인하고 풀어줍니다.
kafka 서버 구성
- $ vi ~/kafka/config/server.properties
- 맨 밑에 delete.topic.enable = true 추가해 주고
- kafka 로그가 저장되는 디렉토리를 변경해 줍니다.
- log.dirs=/home/kafka/logs
zookeeper, kafka 서비스를 보다 쉽게 실행 및 중지할 수 있도록 systemd에 파일 생성
- $ vi /etc/systemd/system/zookeeper.service
- [Unit]
- Requires=network.target remote-fs.target
- After=network.target remote-fs.target
- [Service]
- Type=simple
- User=kafka
- ExecStart=/home/kafka/kafka/bin/zookeeper-server-start.sh /home/kafka/kafka/config/zookeeper.properties
- ExecStop=/home/kafka/kafka/bin/zookeeper-server-stop.sh
- Restart=on-abnormal
- [Install]
- WantedBy=multi-user.target
- $ vi /etc/systemd/system/kafka.service
- [Unit]
- Requires=zookeeper.service
- After=zookeeper.service
- [Service]
- Type=simple
- User=kafka
- ExecStart=/bin/sh -c '/home/kafka/kafka/bin/kafka-server-start.sh /home/kafka/kafka/config/server.properties > /home/kafka/kafka/kafka.log 2>&1'
- ExecStop=/home/kafka/kafka/bin/kafka-server-stop.sh
- Restart=on-abnormal
- [Install]
- WantedBy=multi-user.target
서비스 시작 및 확인
- $ systemctl start kafka
- $ systemctl status kafka
- $ systemctl enable kafka
- $ systemctl start zookeeper
- $ systemctl status zookeeper
- $ systemctl enable zookeeper
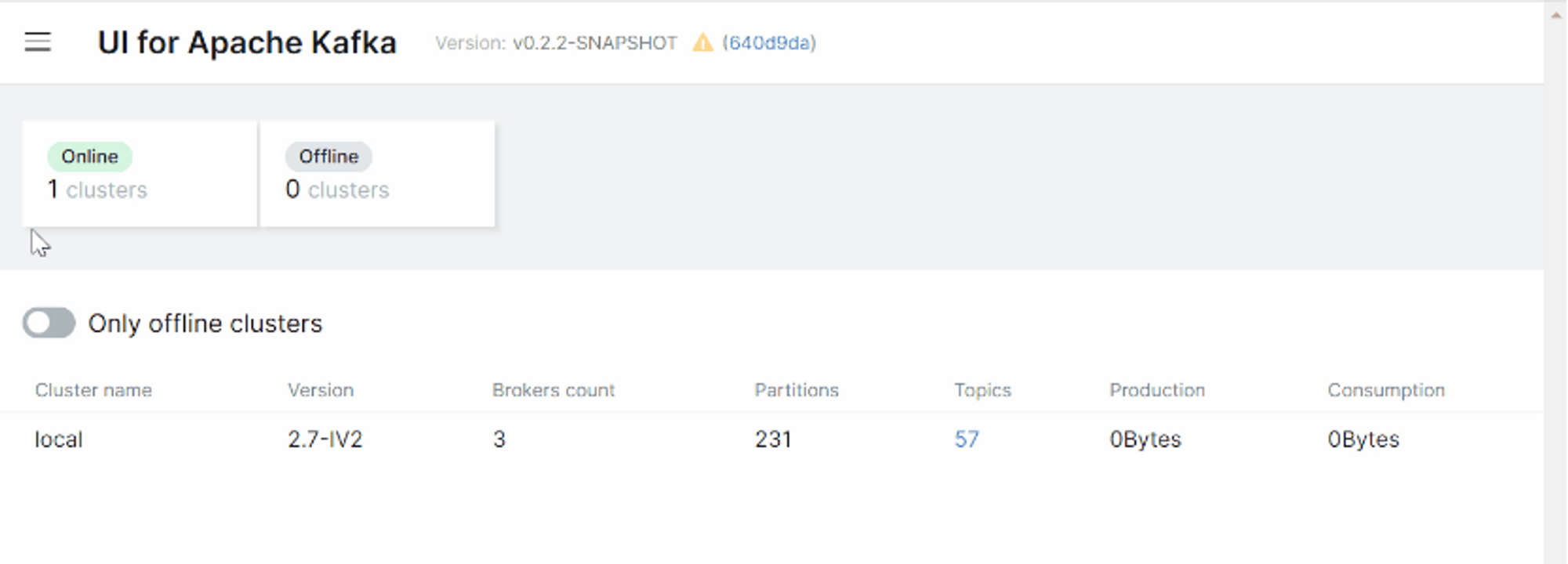
- 카프카 모니터링 툴
UI for Apache Kafka라는 카프카 클러스터를 모니터링하고 관리하는 무료 오픈소스 웹 UI가 있습니다.
Dashboard를 통해 브로커, 토픽, 파티션과 같은 카프카 클러스터의 현황을 확인할 수 있습니다.
UI를 실행하려면 Docker 이미지를 사용하여 실행할 수 있습니다.
도커 이미지 : hub.docker.com/r/provectuslabs/kafka-ui
Dashboard를 통해 브로커, 토픽, 파티션과 같은 카프카 클러스터의 현황을 확인할 수 있습니다.
UI를 실행하려면 Docker 이미지를 사용하여 실행할 수 있습니다.
도커 이미지 : hub.docker.com/r/provectuslabs/kafka-ui
- 백그라운드에서 Docker 컨테이너를 시작합니다.
- docker run -p 8080:8080 \
- -e KAFKA_CLUSTERS_0_NAME=local \
- -e KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS=kafka:9092 \
- -d provectuslabs/kafka-ui:latest
- 이후 http://localhost:8080에서 웹 UI에 접속합니다.
- 환경변수를 이용해 추가구성이 가능합니다.
Kafka 서버를 구성 후 재부팅을 했을 때 서비스가 제대로 실행되지 않는다면
- /home/kafka/logs/meta.properties
- cluster.id 부분을 주석처리하고 서비스를 재시작하면
- 작동이 되는 걸 확인할 수 있습니다.
-
 이전글
이전글 K8s내에 Ceph Storage Cluster 구성 (Multi Node)오픈소스 스토리지 클러스터를 K8s내에 구성하기 K8s내에 Ceph Storage Cluster 구성 Kubernetes는 여러 스토리지 선택지가 있지만, 그중 온프레미스 환경에서 관리가 쉽고 강력한 성능을 내는 Ceph이 있습니다. Ceph Storage Cluster는 안정적이며, 높은 성능과 Block, File, Object 스토리지로 다양하게 사용...2023.02.14
K8s내에 Ceph Storage Cluster 구성 (Multi Node)오픈소스 스토리지 클러스터를 K8s내에 구성하기 K8s내에 Ceph Storage Cluster 구성 Kubernetes는 여러 스토리지 선택지가 있지만, 그중 온프레미스 환경에서 관리가 쉽고 강력한 성능을 내는 Ceph이 있습니다. Ceph Storage Cluster는 안정적이며, 높은 성능과 Block, File, Object 스토리지로 다양하게 사용...2023.02.14 -
다음글
 k8s에서 외부 Ceph Storage Cluster를 기본 StorageClass로 사용하기다른 용도로 사용 중인 Ceph Storage를 Kubernetes에서도 이어 사용할 수 있습니다. k8s에서 외부 Ceph Storage Cluster를 기본 StorageClass로 사용하기 Kubernetes에서 스토리지 클래스로 사용할 수 있는 스토리지 종류는 다양합니다. Local, AWS EBS, AzureFile, AzureDisk, CephF...2023.01.27
k8s에서 외부 Ceph Storage Cluster를 기본 StorageClass로 사용하기다른 용도로 사용 중인 Ceph Storage를 Kubernetes에서도 이어 사용할 수 있습니다. k8s에서 외부 Ceph Storage Cluster를 기본 StorageClass로 사용하기 Kubernetes에서 스토리지 클래스로 사용할 수 있는 스토리지 종류는 다양합니다. Local, AWS EBS, AzureFile, AzureDisk, CephF...2023.01.27
PLEASE WAIT WHILE LOADING...